Turning your benched AI / Machine Learning models into value: How to operationalize your AI / ML models with Cumulocity IoT

Authors: @Nick_Van_Damme1@kanishk.chaturvedi
Introduction
Artificial Intelligence (AI) and Machine learning (ML) have become a ubiquitous part of modern technology, as they help deliver insights otherwise hidden in data for improved decision making and possibly automated responses or actions. Combine AI/ML with IoT, you can now leverage the large amounts of data generated by connected devices for learning based on real-world data and apply those learnings in use-cases ranging from image and speech recognition to predictive maintenance and anomaly detection.
With Cumulocity IoT we provide a product and tooling to do exactly that: 1) connect machines, collect the raw machine data, and make it accessible for ML model training in your data science tool of choice; 2) focus on the operational aspects of the Machine Learning lifecycle, which involves applying a trained model to the incoming IoT data to obtain predictions, scoring, or insights in the cloud and/or at the edge.
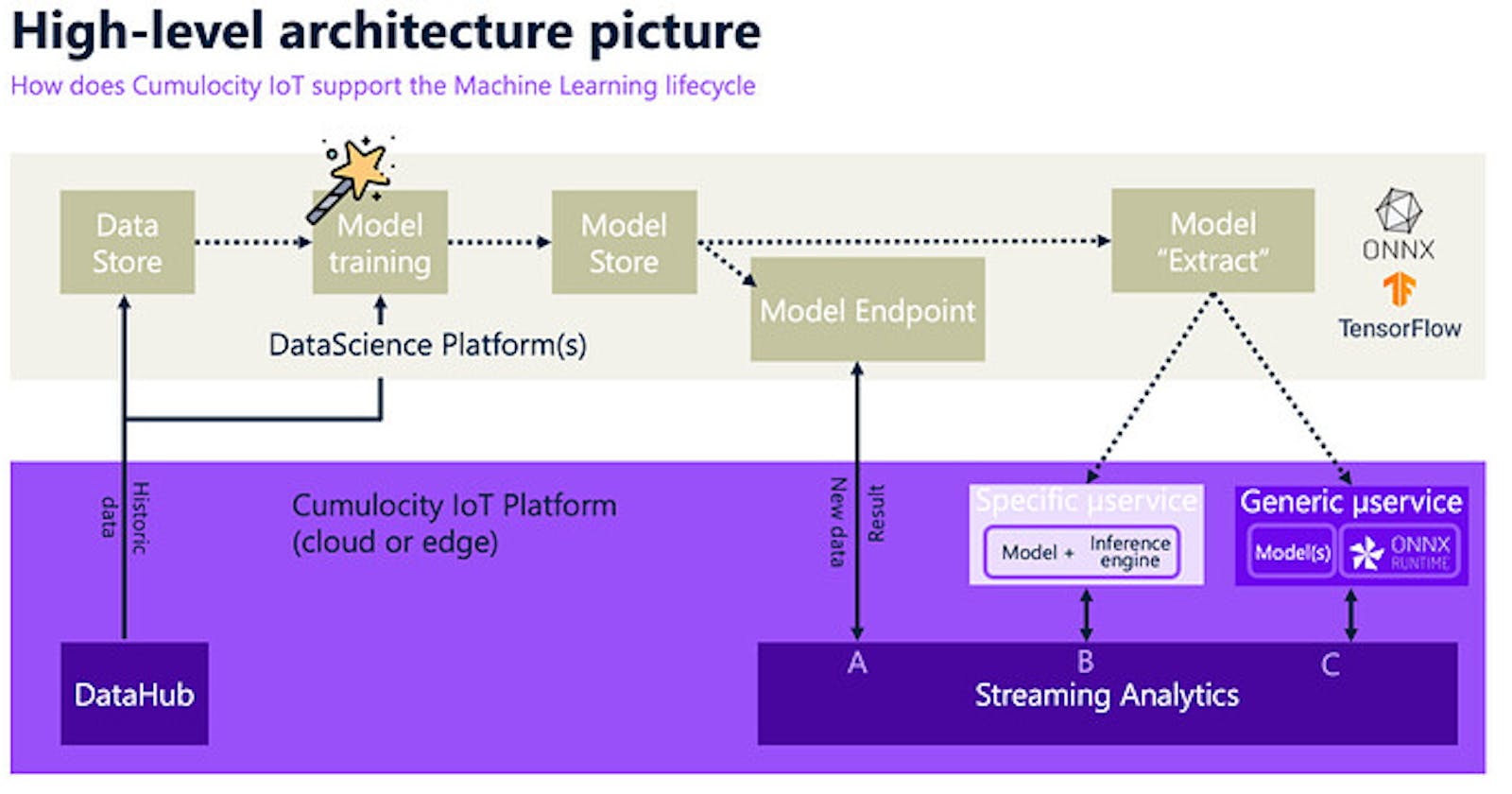
This article explores the steps needed to realize an end-to-end Machine Learning solution leveraging the Cumulocity IoT platform and integrated Data Science & Machine Learning (DSML) components/tooling/platforms, which could be Open-Source components such as TensorFlow and/or tooling from some of our leading ML partners such as Microsoft Azure, AWS (Amazon Web Services), IBM or Boon Logic. The image below illustrates the steps we will walk you through from a high-level architecture perspective, starting with providing the data via Cumulocity IoT DataHub, training the model, making it available for various deployment scenarios (identified as A/B/C, see later) to integrate in a workflow with Cumulocity IoT Streaming Analytics.

Step0: Making the data available for developing Machine Learning models.
All ML use-cases start with (next to defining the objective of the use-case) defining the data-requirements and compiling a set of historical IoT data for training purposes. The IoT data, which is ingested from the connected devices, machines & equipment is retained in the Operational Store of Cumulocity IoT for a limited amount of time. To support long-term (and cost-efficient) storage, as well as easy data extraction, offloading and/or querying for the purpose of developing Machine Learning models, the DataHub add-on product is suggested.
Check out the Cumulocity IoT documentation and this TechCommunity article for more information.
Step1: Create and BYO (Bring Your Own) ML model.
There is a wide variety of Open-Source libraries (e.g., Tensorflow®, PyTorch, Keras, Scikit-learn) and commercial 3rd party tooling (e.g., Microsoft Azure Machine Learning, Amazon SageMaker, IBM Watson, MATLAB, Google Cloud) available for developing machine learning models. As such, Cumulocity IoT offers you the flexibility to have your data science team remain working in their own optimized technology stack but still leverage their results in the field.
Some examples of model creation in the mentioned tools that can inspire you:
Note: In the next step we will look at deploying the created model for inferencing or model scoring. When deploying outside of the training environment, it is important to consider the portability of your model to a different platform. To overcome potential issues, a community of partners has created the Open Neural Network Exchange (ONNX) standard for representing machine learning models, allowing models from many frameworks, including the ones mentioned earlier, to be exported or converted into the standard ONNX format. Once your model is in the ONNX format, you can be sure they are able to run on a variety of platforms and devices.
Step2: Deploying your AI/ML model.
In practice, we see 2/3 frequently used scenarios for deploying your AI/ML model, depending on the requirements of your use-case & and the skill-level/set of your team:
External hosting
Embedded hosting. custom inference microservice
Embedded hosting, generic inference environment

Let’s dive deeper into each of the 3 scenarios!
Scenario A: External hosting
In this scenario, you leverage the ML execution environment of a 3rd party, which is typically closely related to the 3rd party used to create & train the ML model in Step1. The execution environment of the 3rd party exposes an endpoint, which can be used for sending input readings and returning the model scoring output.
Using externally hosted ML models offers advantages such as scalability, reduced infrastructure management, and access to cutting-edge AI/ML capabilities, allowing you to focus on your core functionality and leverage state-of-the-art machine learning without the burden of maintaining infrastructure.
From an architectural perspective, scenario A looks like this:

This scenario is illustrated in more detail in this TechCommunity article
Scenario B: Embedded hosting using custom microservice.
In this scenario, you create & deploy a custom Cumulocity microservice which includes:
an “extract” of the ML model created & trained in Step1,
the relevant libraries for inferencing,
a POST request endpoint for sending input readings and returning the model scoring output.
This approach provides greater control over model customization, data privacy by ensuring sensitive data remains within the platform’s environment; and offers lower latency as data processing occurs within the platform’s environment, reducing the need for external data transfers and potential network-related delays.
From an architectural perspective, scenario B looks like this:

This scenario is illustrated in more detail in this TechCommunity article
Scenario C: Embedded hosting using generic microservice.
In this scenario, you (create &) deploy a Cumulocity microservice which has been purposely built to work generically with specific type(s) of model “extracts”, that are hosted alongside the microservice, e.g., within the Cumulocity file repository. Like scenario B, this microservice includes a POST request endpoint for sending input readings -this time complemented with the reference to the model of choice- and returning the model scoring output.
Similar to scenario B, this approach provides greater control over model customization, data privacy and latency concerns. When you’re considering to grow the number of deployed models, this approach provides a more scalable framework with shared inference resource consumption, and/or allows you to potentially offer your end-users a platform to provide their own custom models.
From an architectural perspective, scenario C looks like this:

A TechCommunity article to illustrate this scenario is currently under construction.
Step3: Setting up a model execution workflow.
Once the AI/ML model is deployed, you need to set up a workflow to
process the incoming data,
pass it to the deployed AI/ML model,
receive the model output,
process the model output to make decisions / create events, alarms, etc.
All 3 articles referenced above, illustrate 1 of various scenarios to leverage the Streaming Analytics tooling (either Analytics Builder or EPL apps) provided with the Cumulocity IoT platform to orchestrate the model execution workflow. More information on the specific Streaming Analytics tooling can be found in the Cumulocity IoT documentation
Summary
This article guided you through the practical steps you can take to operationalize your AI / Machine Learning model with Cumulocity IoT, and as such nicely illustrates the add value which the Cumulocity IoT platform brings in regards to your otherwise benched AI / Machine Learning models

Closing remarks
In the article, we have not considered where your AI / ML model should be deployed to deliver on your use-case in production; this could either be in the cloud or at the edge. As the Cumulocity IoT platform is available in the cloud and/or at the edge with almost similar capabilities, it can hence support your use-case both in cloud or edge and irrespective of whether your model is externally hosted or embedded.
In case you do not have access to tooling / expertise in-house for the BYO Model and/or are looking for a very specific AI / ML use-case such as e.g., predictive maintenance, there are more out-of-the-box solutions that we can recommend. For example, we have partnered with BoonLogic who provide machine-learning-based anomaly detection capabilities with their Amber product. This product can be embedded as a custom microservice within Cumulocity IoT (i.e., scenario B) and can be integrated using Streaming Analytics. To facilitate the integration even further, a plugin has been created consisting of an integration microservice to manage the communication between Cumulocity and BoonLogic Amber + a set of front-end widgets to perform the configuration and visualize the output of the anomaly detection. More information can be found on https://github.com/SoftwareAG/Cumulocity-Amber-Boon-Logic/