The Cumulocity IoT Domain Model - How to design a good domain model

Introduction
In the first article I explained in detail why it is important to have a good domain model before implementing your IoT solution on top of Cumulocity IoT.
In this article I will describe, on examples, how you can leverage the Cumulocity IoT Domain Model and design a “good” model!
Let us start with a very rough introduction to the Cumulocity IoT Domain model.
Overview Cumulocity IoT Domain Model
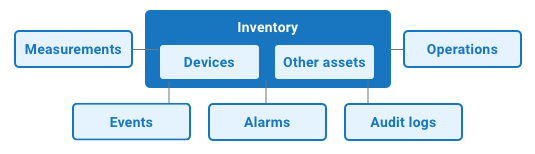
Cumulocity IoT Domain Model is split in several collections:
Inventory - stores meta & representable data about devices, assets and any other master data
Measurements - stores transactional & historical numeric time series data
Events - stores transactional & historical any data
Alarm - stores transactional & historical alarm data
Operations - stores transactional downstream data which is meant to be sent to a device
Audit Logs - stores transactional & historical audit records
Important: One important aspect is that always an inventory object (like device or asset) is required to create any other data in other collections.
Transactional and historical data is often referred as “MEAs” for “Measurements, Events, Alarms”. They must always have exactly ONE reference to an inventory object.
Within that general structure, Cumulocity IoT is defining mandatory fields in the JSON objects that have to be set when ingesting the data.
That gives application also a clear way how to search and filter for data. Beside that all structures can be extend with custom data.
One exception is the measurement structure which also defines the general structure of the JSON object to let applications like the UI or also the streaming analytics easily extract values and utilize them. In detail it always has to have one or multiple fragments which again contains one or multiple series only containing “value” + optional “unit”.
Another part of the domain model is the device management library. Here Cumulocity IoT defines a lot of common fragments for device management. This part of the domain model clearly defines names and JSON structures of these fragments.
The difference between MEAs and Inventory data
If we are considering data that originates from devices there are in general two ways to store them. The first would be as a MEA. The other option would be inside the device managed object.
MEAs are used when you need a historical view over a certain time (e.g. the last hour of temperature). Meaning the main operation is a POST / CREATE of new documents in the database. Only in a few cases the device itself makes a PUT / UPDATE on existing records. Because of this the number of documents can be rapidly grow in the database. Therefor retention rules are applied that delete MEAs under defined conditions e.g. after 14 days.
Inventory data has no timestamp (by default). The device managed object is a digital representation of the device. It can be used for example also to persist the current state of your device (e.g. you could at the current value of some sensor as a property of the device). The main operation is a PUT / UPDATE because you don’t want to have multiple objects in the database for them same device. Here no retention rules are applied and the devices must be deleted manually or per API.
In short:
Use Inventory data for meta data describing an object and to persist the current state of the device.
Use MEAs for historical transactional data like sensor values, device events or alarms.
Pro Tip: Combine them when needed. For example write a measurement of a sensor value related to a timestamp AND update a state in the device managed object with the latest value. Of course this information is redundant but when you are especially interested in the current state including sensor values it is more efficient to query just the device object then the measurement collection.
How to design a good device managed object
Let’s first focus the device managed objects. As the managed objects is in center of the domain model it is also needed to create MEA. Therefor it needs to be retrieved efficiently. Here external IDs are very useful.
External IDs
When creating a managed object it gets a generated ID so called internal ID assigned. Devices are recognized by other identifiers like serial numbers, MAC addresses or other UIDs (Unique identifier). In Cumulocity you can assign multiple external IDs to a managed object and vice versa retrieve the managed object searching for an external ID.
Some things you must consider using external IDs:
They should be unique, ideally not only in your tenant but across other tenants
You can use them implement things like physical device replacement with keeping the data on the origin managed object
Check out the full spec of the identity API
Type, Name & custom fragments
When describing a device or asset make use of the type & name for better usability. The type ideally starts with a prefix e.g. “lora_” and should be used for same device classes. The name should be a readable name and should at least contain:
A short description
A UID
Good name example: Multi Sensor 4711.
Bad name example: This is a device or 444FFASV567884345-1 (last one might used for an identifier but is not readable for humans, so add some more context please).
This makes sure you can easily work with multiple devices and can use the query language to easily retrieve devices of the same device class or similar names.
Only fragments reserved for Device Management or Sensor Library should start with the prefix c8y_. Some examples are c8y_IsDevice flagging the managed object as device or c8y_DeviceTypes containing types which are used to provide sample commands from UIs.
Additional data so called “custom fragments” should start with a prefix and a meaningful name e.g. lora_connectivityStatus.
Important: Names used for fragments must not contain whitespaces nor the special characters `. , * [ ] ( ) @ $ / '` .
Of course you can put multiple properties into one fragment but nesting properties could lead to issues when using PUT of the managed object. Because you can only update on fragment level, not on property level. If you want to update just one property in one fragment with multiple properties, you have to send all of them otherwise they are overwritten and deleted. Also for retrieval you can efficiently check if a device has a specific fragment but only using a full-search when searching for properties in fragments including any values.
Good example:
{
"cust_MyProperty1": "Hello World",
"cust_MyProperty2": "Hello too!",
"cust_Tags": [
"Tag1",
"Tag2"
]
}
In this example you can either filter for “fragmentType” cust_MyProperty1 or cust_MyProperty2 and easily update it with PUT. Same goes for the Array cust_Tags but here you have to PUT always the full list not just another Tag which should be added.
Not so good example
{
"cust_Properties": {
"cust_Property1": "Hello World",
"cust_Property2": "Hello too!",
"cust_Tags": [
"Tag1",
"Tag2"
]
}
}
In this example you nest all your properties in cust_Properties. So you can only filter on cust_Properties and with a PUT you always have to set ALL properties otherwise they will be deleted.
Size of the managed object
You have to consider the size of the managed object. When storing all latest values & meta data on the device managed object it might have an impact on your query performance. Try to keep it as lean as possible but also with all describing and required data. Avoid just putting there stuff in high frequency which isn’t needed or, even worst, upload big content like encoded files, pictures etc. to it.
Addiotional Info: The max. size of a managed object is 16 MB in the Mongo DB, but I hopefully made it pretty clear that you shouldn’t come any close to that max value.
To give you a real-world example: In the past all installed software artifacts were attached in a fragment called c8y_SoftwareList. As a device can have 100 even 1000 of software apps installed, this list could grow big pretty fast. While this was working fine for most devices having only a few software apps installed it had a performance impact for the “big” devices. Also it means that you always have to transfer the full list also when you just do a very small update to it.
The solution was to outsource the software list to other managed objects and using child references to retrieve them, but only when this information is needed and not on every GET request anymore.
Make use of hierarchies
In the Inventory you can make use of hierarchies. In detail they are just other managed object but holding a reference to either a parent or child object. There are 3 types of references possible:
Child Devices - Devices which are assigned to other devices. Can have multiple levels of devices helping to make the operation management as easy as possible. The agent which is basically the root of the tree is always stored in the operation in addition to the ID of the device. This makes it easy for the agent to retrieve and get operations pushed and distributed to child devices. Example: An IoT-Gateway that has multiple devices attached.
Child Assets - Everything else that is not a device. Visible in the Cockpit and other apps (not in Device Management). Ideally assets have other assets or devices as relations in a multi-level tree. The leaf should be a device - even this is not technically enforced. Examples: Groups, Container, Building, Solar Park
Child Additions - Extending the data of the parent object. They are not visible on the Standard Apps like Cockpit and Device Management. Ideally additions are the leaf of a tree and doesn’t have other level of hierarchies. Examples: Software List, Services
You can navigate from the root object to the children and vice-versa.
Caution: This concept allows circles which could end in an infinite loop querying devices. Example: Device B is a child of Device A. If you now define Device A as a child of Device B you got a circle which might lead you into an infinite loop when querying the references of one Device.
Permissions in the hierarchies
Luckily the permission behavior is the same in all hierarchies and it is very straight forward.
Whenever you have access permissions (regardless of which) on a certain asset/group/device you will automatically have the same permissions for the whole device, asset and additions hierarchy under this asset/group/device.
You also cannot reduce or revoke the permissions for child devices, assets or additions so keep that in mind when structuring your assets if you want to utilize permissions on asset level (inventory permissions).
How to design good MEAs
For MEAs our design has to be slightly different as this data is historical and should not kept forever in most cases.
Measurement design
The measurement structure is somehow fixed, even it allows custom fragments. It should always contain:
a time stamp as
time- Ideally UTC time format is useda managed object as
sourcea type string as
typeone or multiple
fragmentswith one or multiple
series- with exactly one
valueand an optionalunit
- with exactly one
For the full spec please check out the official Open API documentation about posting measurements
{
"time": "2023-04-25T08:32:00.000Z",
"source": {
"id": "91104794933"
},
"type": "c8y_EnergyConsumption",
"Fragment1": {
"Series1": {
"value": 435,
"unit": "kWh"
},
"Series2": {
"value": 23,
"unit": "kWh"
}
}
}
This structure enables an important pattern: If your time series values, share the same timestamp & device, you might ingest them using ONE request & document only and not using MULTIPLE requests & documents for each single value. Vice versa it is more efficient to retrieve the measurements because of less documents in the database. Also measurements are just POSTed and never updated (PUT).
Of course you can also add custom fragments not following the structure but we would not suggest to do that. For other custom data we suggest to use Events.
Event design
An event requires four properties:
a time stamp as
time- Ideally UTC time format is useda managed object as
sourcea description as
texta type string as
type
For the full spec please check out the official Open API documentation about posting events
In addition you can add multiple custom fragments which hold any kind of flat, complex or array data.
{
"time": "2023-04-25T08:32:00.000Z",
"source": {
"id": "91104794933"
},
"type": "cust_ProducedPart",
"text": "Produced Part Event",
"cust_producedPart": {
"name": "PartName",
"partId": "4711"
},
"cust_partList": [
"Part1",
"Part2"
],
"cust_status": "OK"
}
Events can and should be updated when necessary. Here the same principal as for custom fragment in managed objects apply (see Type, Name & custom fragments). Use nested structure when required, use flatten properties to easily update & filter for events.
Alarm design
An alarm is very similar to events and requires five properties:
a time stamp as
time- Ideally UTC time format is useda managed object as
sourcea description as
texta type string as
typea
severityof values “CRITICAL” “MAJOR” “MINOR” or “WARNING”
For the full spec please check out the official Open API documentation about posting alarms
In addition you can add multiple custom fragments which hold any kind of flat, complex or array data. Still, I would not suggest to do so as the Alarm API does not have a fragmentName and fragmentValue filter in comparison to the Event API. Please use events to store additional information and data and to easily query for them.
{
"time": "2023-04-25T08:32:00.000Z",
"source": {
"id": "91104794933"
},
"type": "cust_TestAlarm",
"text": "I am an alarm",
"severity": "MINOR"
}
Alarms can and should be updated when necessary. Here the same principal as for custom fragment in managed objects apply (see Type, Name & custom fragments). Use nested structure when required, use flatten properties to easily update & filter for alarms.
How to design a good device operation
Operations follow a different purpose than MEAs and managed objects: Sending information / commands downstream to a device or agent. To achieve that efficiently the operation should contain the following content:
an identifier of the device
deviceIdexactly ONE
fragmentcontaining anything meaningful for the device
For the full spec please check out the official Open API documentation about posting operations.
Based on the fragment name the operation will be mapped to MQTT (static) response templates and sent to the device. The fragment therefore defines the type, fragment Name, and content, fragment value, of the operation.
It is NOT recommended to have multiple fragments in one operations as the status could not be clearly assigned to one command. Instead you can either send all information in one fragment or use multiple operations e.g. bulk operations.
{
"deviceId": "91104794933",
"c8y_Command": {
"text": "sudo reboot"
}
}
Summary
In this article you learned how a basic good data design can look like. When following the principles described here you can avoid major mistakes and soon will become a master of data design!

As always the devil is in the detail. There are a lot of edge cases as every data design is different. I would be happy to discuss this with you here in the comments or in the community!
But… we are not done yet!
In the next article I will focus on storing generic key-value pairs & how you can improve your queries.