Performing Machine Learning Inference on Cumulocity IoT Data using Open-Source Frameworks

Introduction
Machine learning (ML) has become a ubiquitous part of modern technology, with applications ranging from image and speech recognition to predictive maintenance and anomaly detection in IoT devices. In this article, I discuss the concept of Machine Learning Inference, which involves applying a trained model to new input data to obtain predictions, scoring, or insights. Furthermore, I demonstrate how to perform such ML inference on Cumulocity (C8Y) IoT data using Open-Source Frameworks. As an alternative to the existing C8Y ML Workbench and ML Engine, this approach provides more freedom to users where they can choose their preferred libraries to train, deploy, and execute their ML models.
This is an introductory article for such approaches, and as a first step, it focuses on one Open-Source ML framework named ONNX Runtime. Here,
I demonstrate how to load and run a trained ML model using ONNX Runtime in a Python environment, as well as how to preprocess input data and postprocess the model output.
This approach would allow users to easily create Python based C8Y Microservice to load and execute ML Training Models developed using their own preferred libraries.
In addition, using Streaming Analytics (EPL app), users can also create workflows to perform ML inferencing on C8Y data by simply calling that Microservice.
Background
Before moving on, let’s quickly understand what the advantages of Open-Source ML frameworks are and why the ONNX Runtime is so popular!
Open-Source ML Frameworks
Open-Source ML framework provide a range of benefits, from cost savings to a large community support to continuous innovation. There are many sophisticated Open-Source ML Framework available in the market, including TensorFlow, PyTorch, Scikit-learn, ONNX (Open Neural Network Exchange), and Keras.
On the one hand, these frameworks provide a wide variety of tools, libraries, and algorithms for developers and data scientists to build and train ML models.
On the other hand, they are typically easier to deploy and integrate into MLOps workflows; mainly due to a built-in support for common deployment platforms such as cloud services, Kubernetes, and Docker.
Additionally, Open-Source frameworks typically have large and active communities that contribute to the development of new features, provide support and documentation, and develop integrations with other tools and technologies commonly used in the MLOps ecosystem. This makes it easier to find resources and examples, as well as to troubleshoot and debug issues that may arise during the deployment and operation of ML models.
ONNX Runtime
So, what exactly is ONNX Runtime?

It is a high-performance inference engine for machine learning models in ONNX format. Its biggest advantages are:
Open-Source and Interoperability: It is completely Open-Source and allows users to train their models in various frameworks such as TensorFlow, PyTorch, and scikit-learn, which can then easily be converted into the ONNX format in order to run them using ONNX Runtime.
Multiple Deployment Targets: It supports a wide range of hardware devices, including CPUs, GPUs, and FPGAs, and it can be used across multiple platforms, such as Windows, Linux, and macOS.
Model Quantization: It allows models to be compressed and optimized for inference on resource-constrained devices. By reducing the size of the model, quantization enables faster inference times and reduces memory usage.
Automatic Graph Optimization: It optimizes the graph of the model for different hardware platforms. This includes techniques such as kernel fusion, constant folding, and other optimizations that can significantly improve the speed of model inference on different platforms.
Overall, ONNX Runtime provides a powerful and flexible tool for deploying machine learning models in a wide range of environments, from high-performance cloud-based services to low-power edge devices. With its support for model quantization and automatic graph optimization, it offers a range of features to improve the speed and efficiency of model inference.
Now that we know the basics, let’s start creating the microservice and the workflow!
Prerequisites
To follow this guide, you need the following:
A Cumulocity (Trial) Tenant
IDE (e.g. Visual Studio Code)
How to create a C8Y Microservice for ONNX Runtime
This section describes how to create a Python-based C8Y Microservice to load and run a trained ML model using ONNX Runtime.
For the demonstration purpose, I train a classification model for Activity Recognition using a Smartphone (more details of this use case are available over Cumulocity IoT Machine Learning guide). In a nutshell, this model is trained to get the accelerometer readings from the smartphone registered over Cumulocity as input and performs classification to predict/score the activity for the individual accelerometer reading. For simplification, I trained this model as binary classification; that means there can only be two activity outputs: SITTING and MOVING.
Please note: The instruction for model training is not within the scope of this article. Numerous training models in the ONNX format are already available over ONNX-Github. Similarly, the training models from other frameworks like TensorFlow and PyTorch can also be easily converted into ONNX format. The instructions are available on their respective websites.
Once the model is trained and saved as ONNX format, we can start creating the Python-based microservice with the help of the guidance available on Cumulocity IoT Microservice SDK guide.
Step 1: Creating a Python web server
The below code creates the application.py file and uses Python 3 with a Flask microframework which enables simple exposing of endpoints and an embedded HTTP server.
#!flask/bin/python
from flask import Flask, request, jsonify
import onnxruntime as rt
import numpy as np
import json
# Create a Flask application
app = Flask(__name__)
# Hello world endpoint
@app.route('/')
def hello():
return "<p>Hello, This is a Specific Microservice for a deployed ONNX Model!</p>"
# Verify the status of the microservice
@app.route('/health')
def healthjson():
mydata = {
"status" : "UP"
}
return jsonify(mydata)
# Load the ONNX model
sess = rt.InferenceSession("model/onnx-model/cumulocity_classification_model.onnx")
# Define an API endpoint that will receive input data from a client
@app.route('/predict', methods=['POST'])
def predict():
# Get the input data from the request
input_data = request.json["inputs"]
# Get all values from dictionary as a list (sorted according to the key names to ensure the correct sequence of x,y,z values)
list_values = [value for key, value in sorted(input_data.items())]
# Perform preprocessing on the input data
input_array = np.array(list_values).reshape((1, 3, 1)).astype(np.float32)
# Get the names of the input and output nodes of the ONNX model
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[0].name
# Pass the preprocessed input data to the ONNX Runtime
output = sess.run([output_name], {input_name: input_array})
# Convert the prediction output to a JSON object
output_data = {"output": output[0].tolist()}
# Return the prediction output as a JSON response
return jsonify(output_data)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=80)
The application is configured to run on port 80 – which is required for microservices – and exposes three endpoints:
/returns a basic introductory message/healthis the common endpoint to verify if a microservice is up and running./predictis a POST Request endpoint; which is used to send the input readings to the microservice and returns the output based on the model scoring calculated by ONNX Runtime.
Within the code, the relevant Python libraries are imported such as onnxruntime, numpy, and flask. The function InferenceSession is used to load the trained ONNX model. It is also possible to load the ONNX models by using a URL (in case the model is stored over an external Cloud).
Before passing the input values to the ONNX Runtime, it is important to preprocess them to ensure that the model interprets the data in the correct format. For this example, the line
input_array = np.array(list_values).reshape((1, 3, 1)).astype(np.float32)
prepares the input data for inference by creating a 3D tensor with the correct dimensions and dtype (as float32) that can be passed to the ONNX Runtime session.
Please note: Preprocessing input data is an essential step for ONNX Runtime as it helps to optimize the performance of the model during inference. The input data may need to be transformed or scaled to fit the model’s requirements, such as input shape, data type, or range of values. By preprocessing the input data, we can ensure that the input data is in the expected format and that the model can make accurate predictions. In addition, preprocessing can help reduce the size of the input data, leading to faster inference times and lower memory usage.
After preprocessing the input data, it is passed to the Inference engine using the lineoutput = sess.run([output_name], {input_name: input_array})
That returns the output which can be post processed in order to transform it into a more understandable form.
Step 2: Create the Dockerfile
The next step is to create a Dockerfile in order to build a Docker image for this application. It should be in the same directory as the application.py script and with the following content:
FROM python:3.8-slim-buster
#Copy the application.py file and the ONNX Model file
COPY application.py /
COPY model/ /model/
#Install necessary libraries
RUN apt-get update && \
apt-get install -y libgomp1 && \
pip install --upgrade pip && \
pip install flask numpy onnxruntime && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
ENTRYPOINT ["python"]
CMD ["-u", "application.py"]
This build uses Python slim-buster. It helps in creating lightweight and efficient Docker containers for Python-based applications and is also compatible with onnxruntime. The instructionpip install flask numpy onnxruntime
installs the required Python library using the pip installer.
Step 3: Add the application manifest
The microservice manifest file cumulocity.json is required for the application. We can create that file with the following content:
{
"apiVersion": "1",
"version": "1.0.0",
"provider": {
"name": "Cumulocity"
},
"isolation": "MULTI_TENANT",
"requiredRoles": [
],
"roles": [
]
}
Step 4: Build the application
We can execute the following Docker commands to build the Docker image and save it as image.tar:
sudo docker build --no-cache -t specific-onnx-1 .
sudo docker save specific-onnx-1 > "image.tar"
Then pack image.tar together with the manifest cumulocity.json into a ZIP file.
sudo zip specific-onnx-1 cumulocity.json image.tar
The resulting specific-onnx-1.zip file contains the microservice and it is ready to be uploaded to the Cumulocity IoT platform.
Step 5: Run the example
Uploading the specific-onnx-1.zip into the platform can be done via the UI. In the Administration application, we can navigate to Ecosystem > Microservices and click Add Microservice. Upload the ZIP file of the microservice and then click Subscribe.
Step 6: Test using Postman
Once the microservice is successfully uploaded, we can test its functionality (in this case, with Postman).
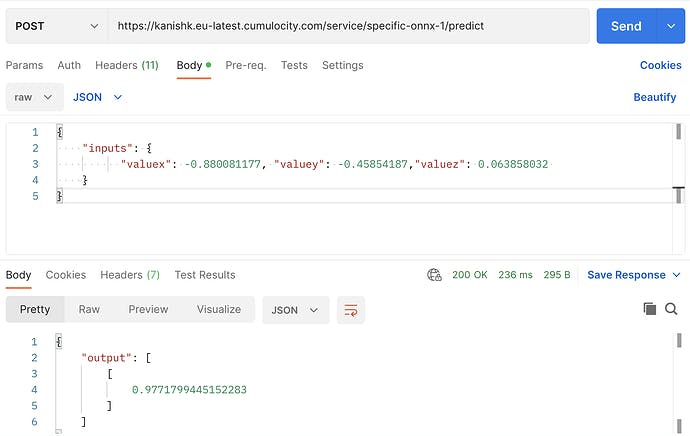
As we can see, the predict function of the microservice can be accessed as <URL>/service/specific-onnx/predict endpoint. The URL will be the tenant URL along with the Authorization header. The input data with a sample accelerometer can be passed as a JSON object as shown in the screenshot.
This request returns a probability output value that indicates the recognition scoring of this accelerometer reading. In this case,
when the probability is closer to 1, the activity is MOVING; and
when the probability is closer to 0, the activity is SITTING.
How to create an ML Inference workflow using Streaming Analytics
This section shows how to create an EPL app to process incoming data and then pass it to the Machine Learning model in the newly created ONNX Runtime microservice to make decisions on the processed data. Apama EPL (Event Processing Language) is a flexible and powerful “curly-brace”, domain-specific language designed for writing programs that process events.
/**
* This application queries a separate microservice (machine learning)
* to make predictions based on the Activity Recognition use case in the
* documentation. However, instead of Zementis, it now queries an ONNX RunTime Microservice.
*/
using com.apama.cumulocity.CumulocityRequestInterface;
using com.apama.correlator.Component;
using com.apama.cumulocity.Alarm;
using com.apama.cumulocity.Event;
using com.apama.cumulocity.Measurement;
using com.apama.cumulocity.FindManagedObjectResponse;
using com.apama.cumulocity.FindManagedObjectResponseAck;
using com.apama.cumulocity.FindManagedObject;
using com.softwareag.connectivity.httpclient.HttpOptions;
using com.softwareag.connectivity.httpclient.HttpTransport;
using com.softwareag.connectivity.httpclient.Request;
using com.softwareag.connectivity.httpclient.Response;
using com.apama.json.JSONPlugin;
/**
* Call another microservice
*/
monitor ActivityRecognitionONNX {
CumulocityRequestInterface requestIface;
action onload() {
requestIface := CumulocityRequestInterface.connectToCumulocity();
// Replace yourDeviceId with the value of your device id
string yourDeviceId:=<yourDeviceId>;
listenAndActOnMeasurements(yourDeviceId, "specific-onnx-1");
}
action listenAndActOnMeasurements(string deviceId, string modelName)
{
//Subscribe to the Measurement Channel of your device
monitor.subscribe(Measurement.SUBSCRIBE_CHANNEL);
on all Measurement(source = deviceId) as m {
if (m.measurements.hasKey("c8y_Acceleration")) {
log "Received measurement" at INFO;
dictionary < string, any > RECORD:= convertMeasurementToRecord(m);
log "Sending record to ONNX RunTime - " + JSONPlugin.toJSON(RECORD) at INFO;
//Define the Root of your ONNX Microservice
string REQUEST_ROOT:= "/service/specific-onnx-1/predict";
Request onnxRequest:=
requestIface.createRequest("POST", REQUEST_ROOT, RECORD);
onnxRequest.execute(onnxHandler(deviceId).requestHandler);
log "EPL execution completed." at INFO;
}
}
}
action convertMeasurementToRecord(com.apama.cumulocity.Measurement m)
returns dictionary < string, any >
{
dictionary < string, any > json := { };
json["accelerationX"] := m.measurements.
getOrDefault("c8y_Acceleration").
getOrDefault("accelerationX").value;
json["accelerationY"] := m.measurements.
getOrDefault("c8y_Acceleration").
getOrDefault("accelerationY").value;
json["accelerationZ"] := m.measurements.
getOrDefault("c8y_Acceleration").
getOrDefault("accelerationZ").value;
dictionary < string, any > inputs := {"inputs":json};
return inputs;
}
event onnxHandler
{
string deviceId;
action requestHandler(Response onnxResponse)
{
integer statusCode:= onnxResponse.statusCode;
if (statusCode = 200)
{
dictionary<string, any> outputs := {};
//extract the results from the Output payload from the response.
//Since it is a sequence<sequence<float>> response, the float prediction value needs to be extracted from the response
any myresult := onnxResponse.payload.data.getEntry("output");
sequence<any> extract1 := <sequence<any>> myresult;
sequence<any> extract2 := <sequence<any>> extract1[0];
float extract3 := <float> extract2[0];
outputs["probability"] := extract3;
//Perform a logic to differentiate Moving and Sitting labels
string label;
if(extract3>0.95){
label := "MOVING";
}
else{
label := "SITTING";
}
//Create an Event with the Probability value
send Event("",
"ActivityRecognitionEvent",
deviceId,
currentTime,
"Activity Recognized as "+label,
outputs) to Event.SEND_CHANNEL;
}
else
{
log "onnx response :" +
onnxResponse.payload.data.toString()
at INFO;
}
}
}
}
This EPL app is developed by referring to the Cumulocity IoT Streaming Analytics guide and more details of the subsequent instructions can be found in the guide. In summary, this app
processes the incoming data from smartphone registered over Cumulocity,
pass the data to the
specific-onnx-1microservicereceives the probability output from the microservice
create an Event on the device with the details of the probability output (if the probability > 0.95, activity is MOVING else activity is SITTING.
After creating the EPL app, we can simply activate it. This would allow reading the incoming data from a registered Smartphone and processing them to the ONNX Runtime microservice using the EPL app. Below is a screenshot from Device Management showing individual events indicating the activity for each measurement.

Conclusions & next steps
As demonstrated, this is just a first step towards performing ML Inference using sophisticated Open-Source ML frameworks. Similar workflows can very easily be created for other use cases such as image classification, video analytics, and anomaly detection. Similarly, other frameworks like TensorFlow, Pytorch can also be used for creating such microservices and workflows.
For simplification, the loading of the ONNX model and preprocessing & postprocessing steps are included in the same application.py file in this example. However, in real-world scenarios with MLOps pipeline, it is beneficial to separate the ONNX model, preprocessing, and postprocessing steps as it allows for greater flexibility and modularity in the development and deployment of machine learning models. By separating these steps, each component can be developed and maintained independently, allowing for more efficient collaboration among team members. Additionally, it enables the reuse of preprocessing and postprocessing steps across multiple models, saving time and effort. There will be another subsequent article for demonstrating such MLOps pipelines with ONNX Runtime. Stay Tuned!!!
Meanwhile, if you have any suggestions for ML use cases that you would like to cover using such workflows, please feel free to write them down in the comments and I’ll be happy to review them!